From Monoliths to Multitudes: Why Agent Swarms Beat Giant Models on the Road to AGI
If general intelligence is on the horizon, simply making one model larger won't get us there. We need to create networks of specialized models that can communicate, debate, and share their knowledge.
by Oguzhan Baser (oguzhan@theseus.network) and Eric Wang (eric@theseus.network)
Here's a HumanEval test result that keeps coming back to us. Take GPT-3.5 and put it in a simple agent loop where it can call tools, critique itself, and bounce ideas off other instances of itself. It ends up beating GPT-4 run standalone. Run the same loop on GPT-4 and you land roughly where an experienced human programmer would. GPT-4 has about ten times the parameters of GPT-3.5, and on this benchmark that mostly didn't matter.
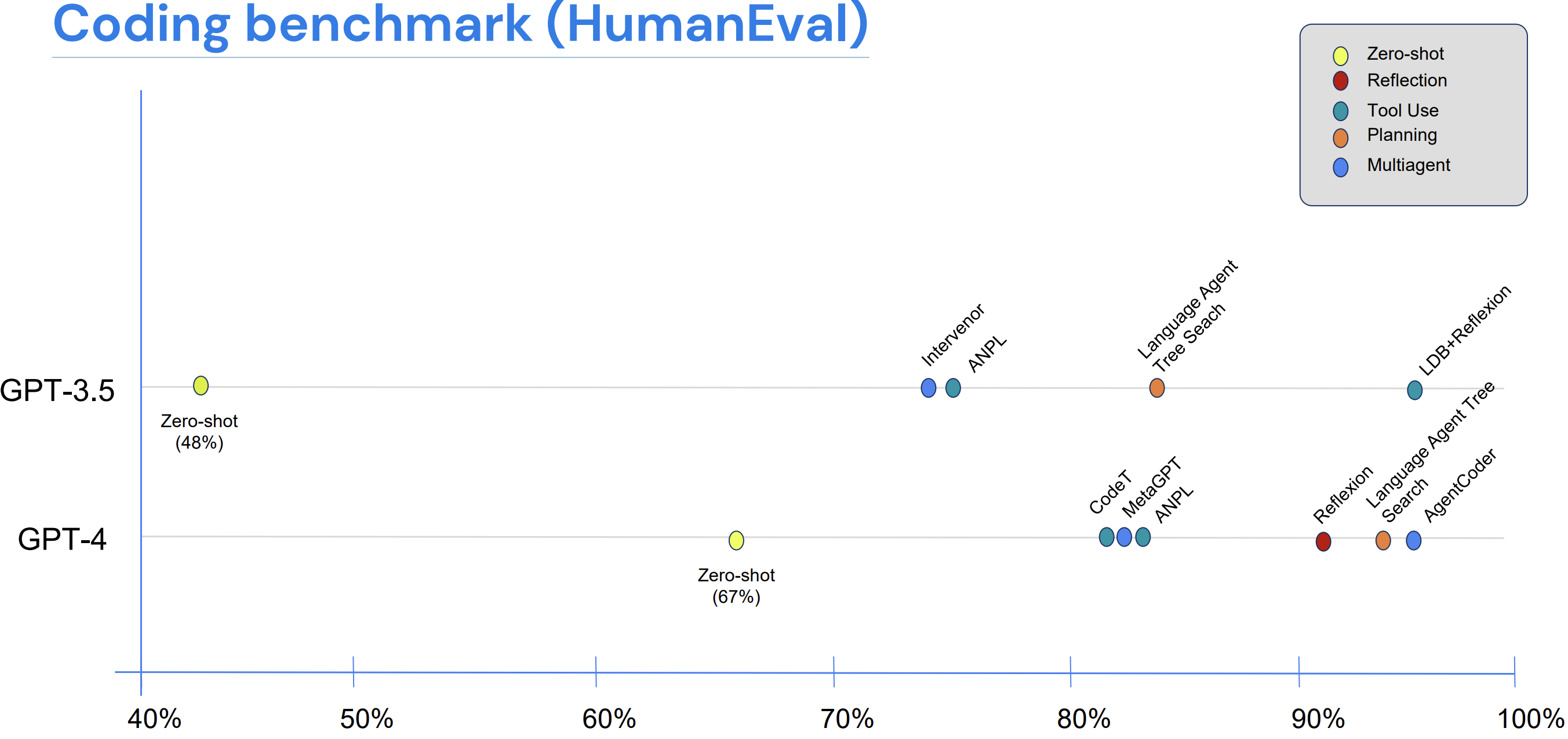
Compiled by Andrew Ng, DeepLearning.AI, 2024 [14], drawing on AgentCoder, MetaGPT, LATS, Reflexion, and others. HumanEval coding benchmark. Zero-shot GPT-3.5 hits 48 percent. Zero-shot GPT-4 hits 67 percent. Put either in an agent loop (reflection, tool use, planning, multi-agent) and the smaller model crosses the larger one; the larger one crosses expert-human performance.
We think that result is a glimpse of where the next several years go. If general intelligence is coming at all, we suspect it won't come from simply building bigger and bigger models. We expect it comes via networks of specialized models that interact, criticize, and collaborate. That's been the road for a while now. Monolithic models like GPT-3 gave way to mixture-of-experts (different sub-networks handling different parts of the input inside one model), and MoE gave way to the tool-using assistants people use today. At every step, the models' mistakes got less correlated. The next step takes the agents fully outside any single model.
I. The Single-Model Fallacy

The main game of the last decade has been that capability scales with parameters: build a big enough network and you get more of whatever you wanted. On easier benchmarks that has roughly held. On harder work (multi-step, multi-modal, tool-using), scaling on its own starts to plateau, and adding more parameters doesn't reliably fix it.
Scaling gives you real things. Better quality on familiar distributions, compressed statistical regularities, and the kind of natural-language fluency that didn't exist five years ago. What scaling does not reliably give you is the stuff that actually matters in production: systematic generalization across modalities and tools, grounded action with traceable steps, planning under hard constraints, and robustness to inputs that drifted outside the pretraining distribution.
A single model carries a single bias. It does well where the bias fits and badly where it doesn't, and the more complex the task, the more often that mismatch shows up. The same four failure modes recur.
Errors propagate. A misreading early in the chain feeds the calculation that depends on it, and from there feeds the explanation that justifies the calculation.
Modality gaps stay hidden. Text-only pretraining teaches a model to talk about images, tables, and code without teaching it to operate on them at engineering fidelity. Multimodal training narrows the gap but rarely closes it across all three.
Planning lacks separation. When the same system writes a plan, runs it, checks it, and approves it, no component is positioned to catch its own errors.
Accountability is opaque. When a one-box pipeline fails, you can't easily tell which capability failed, or why. Just that it did.
Parameter scaling addresses these unevenly. They only really go away when the system is decomposed into specialized agents with explicit logic for combining their outputs.
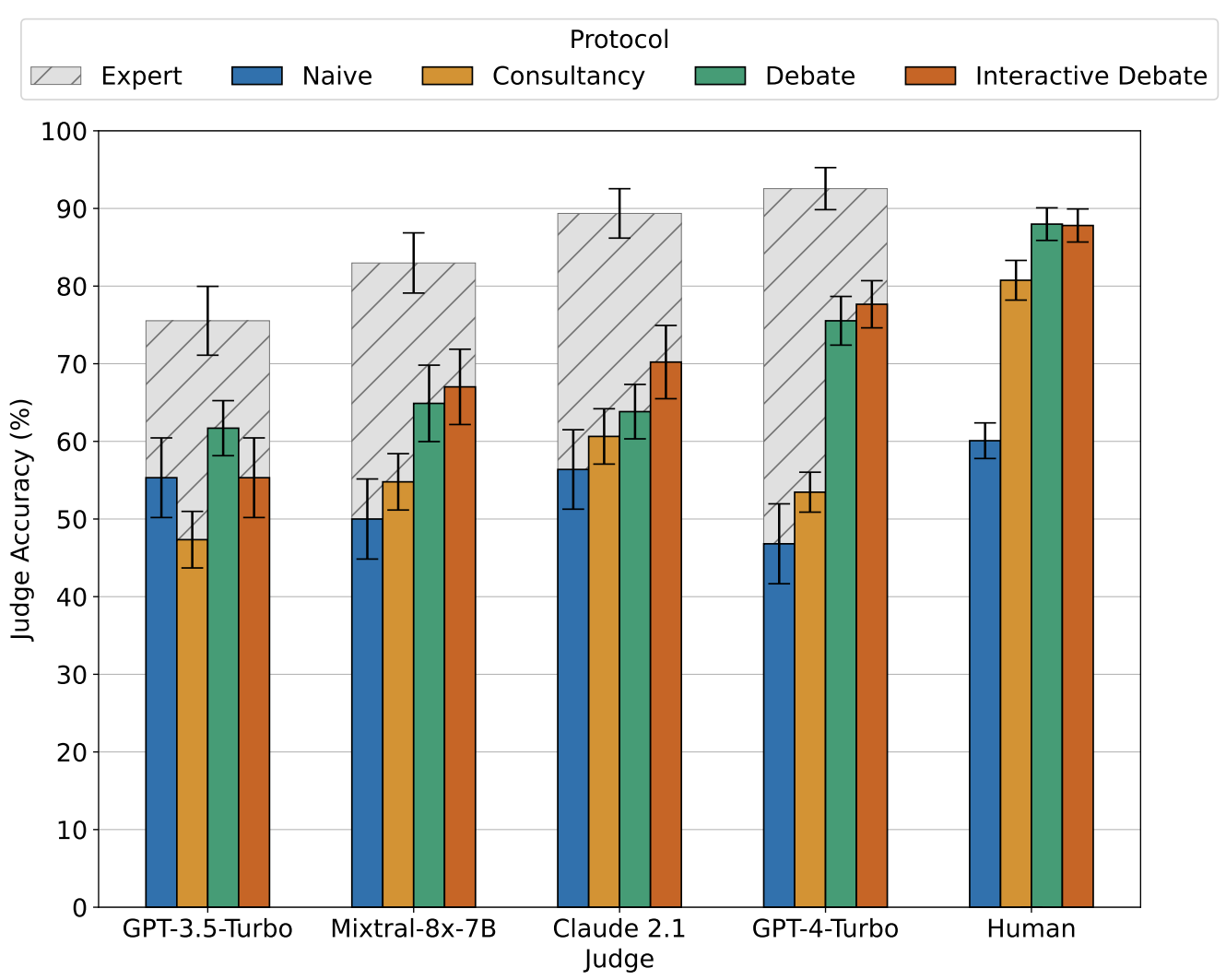
Khan et al., ICML 2024 [10]. Judge accuracy by protocol across five judges (GPT-3.5-Turbo through human). Across the judges tested, debate (and interactive debate) consistently matches or beats single-consultant and naive baselines, with the largest gap appearing for the strongest judges. Hashed bars show what fully informed experts achieve; colored bars show judges working without the source text.
II. Variety Beats Volume
Diverse, complementary sources of evidence tend to produce larger and more reliable gains on hard tasks than parameter scaling does on its own. Three arguments make the point concrete.
The information argument. The total knowable information about a target from inputs decomposes as a chain of conditional terms:
Each term is how much view adds beyond the views before it. Scaling a model on the same view chases diminishing returns inside one term. Adding an orthogonal view (a code executor, a retrieved citation, a depth sensor) opens a whole new term, and that's a term more parameters on can't reach no matter how many you stack. Retrieval supplies facts the model never memorized, execution tools deliver exactness that language models can only approximate, and other modalities carry signals that language alone can't infer.
The error argument. Take specialists with zero-mean errors and pairwise correlation . A late-fusion average has expected squared error roughly
The variance term shrinks as grows, and faster as falls. In our ModalFidelity work [13] we tightened this to a standard exponential bound on classification error (the Bhattacharyya bound):
Error decays exponentially in the number of decorrelated specialists . Decorrelation reduces variance directly, and bias terms pointing in different directions cancel instead of compound. So a diverse panel ends up destroying the correlated part of error that scaling can't reach no matter how big the model gets.
The geometry argument. Real-world problems don't share one structure. Legal reasoning, robotic control, medical tabular data, and audio transcripts each have their own statistical character, and a single model has to learn one parameterization that compromises across all of them. Specialists don't compromise. Each fits its region with fewer parameters and higher fidelity, and a fusion layer spends the global budget across structures instead of stretching one model thin across all of them.
Robustness follows the same pattern. A median or trimmed mean over agents resists outliers, Byzantine-robust aggregation caps the damage from any compromised contributor, and splitting planner from executor from judge prevents any one system from both making and certifying its own mistakes. A monolith is a single point of failure. An ensemble fails smaller and recovers faster.
Not all diversity helps. Two specialists that fail for the same reasons have just duplicated a failure mode rather than added one. Useful diversity is complementary across the things that matter: different modalities, different priors (generative plus symbolic, neural plus constraint solver), different memory horizons, fast reactive agents working alongside slow reflective ones, different training seeds when you can afford the duplication. A panel of capable, decorrelated specialists can match or outperform a single state-of-the-art monolith on complex, coordination-heavy work at the same parameter budget.
The implication for general intelligence is structural rather than incremental. Variety enlarges the information surface and reduces correlated error, while parameter scaling just concentrates more capacity behind a single bias. That's part of why later mixture-of-experts models already outperform earlier dense models several times their size.
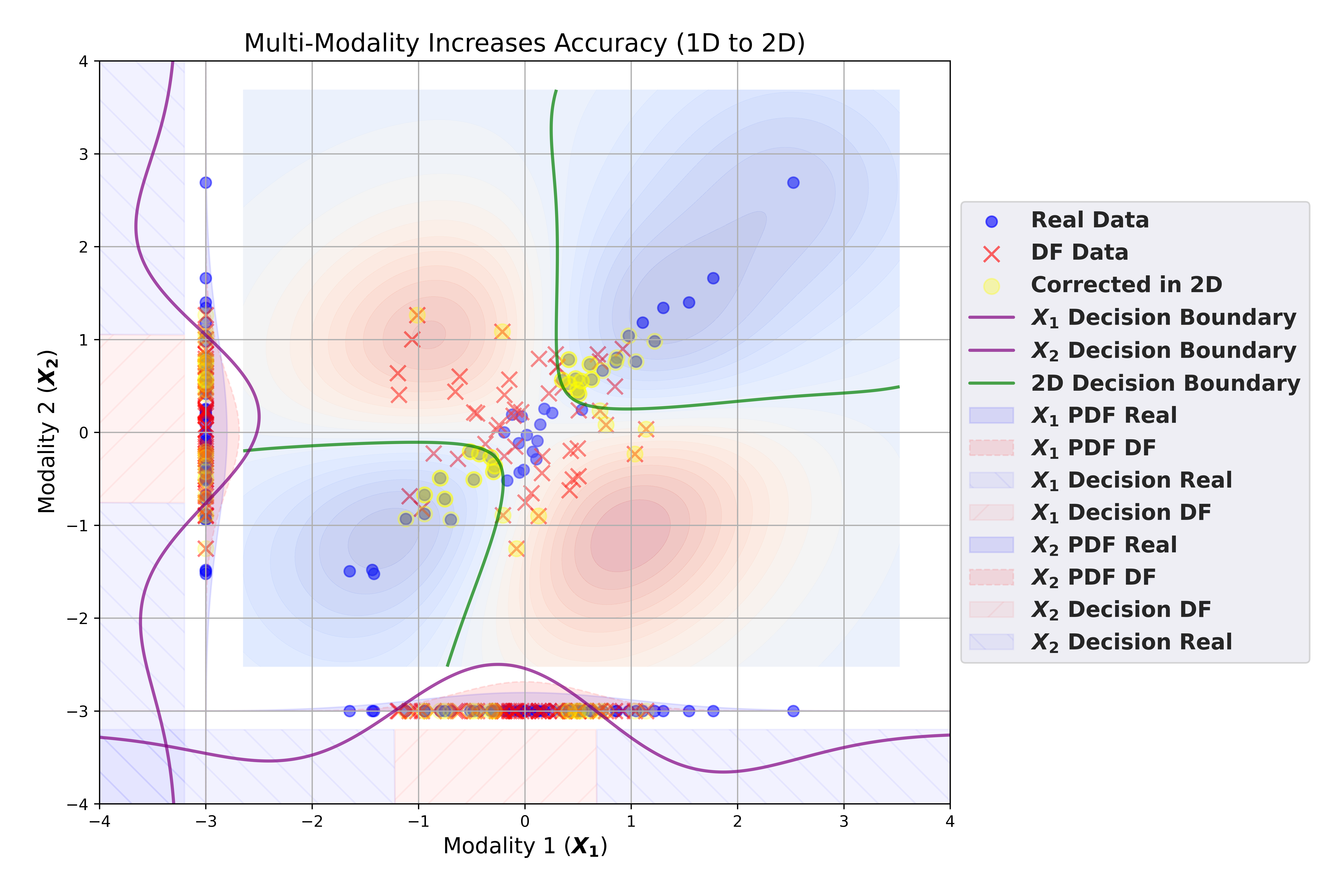
Baser et al., ModalFidelity, TMLR 2025 [13]. Same-size binary classifiers on the same data, evaluated unimodally (modality 1 only, modality 2 only) and bimodally. The 1D decision boundaries cannot separate the corrected class. The 2D boundary, formed by asking whether two views agree, recovers it. Cross-source consistency delivers better accuracy at lower cost than enlarging either source alone.
III. Where You Fuse Changes Everything
Variety alone isn't enough. Once you have multiple specialists, the design problem becomes how their outputs combine, and where you place the fusion turns out to matter more for robustness, sample efficiency, and alignment than parameter count does. Four common patterns, roughly in order of how much structure each one imposes.
Early fusion (raw signal). Raw streams (vision, text, audio) get concatenated or cross-attended before representations stabilize. Benefit: maximum cross-modal sharing. Cost: brittle alignment, plus negative transfer whenever any one stream is noisy or adversarial. This pays off when sensor statistics are tightly controlled and paired data is abundant, which is rare outside curated benchmarks.
Mid-level fusion (feature). Each specialist normalizes its domain into a compact embedding, and cross-attention or gated mixing layers handle the combination. This is the practical default for most real systems. Specialization is preserved, context is injected where it matters, and experts can be retrained independently of each other.
Late fusion (decision). Agents vote, average, stack, or defer to a learned arbiter. The output is easy to debug and clean across trust boundaries, which makes it the right choice when components come from different teams or organizations. Byzantine-robust aggregation methods (Krum and similar, developed in Guerraoui et al.'s Robust Machine Learning [5]) cap the influence of any single bad actor in a way that no monolithic decoder can.
Deliberative fusion (oversight and critique). Outputs go through a structured exchange: propose, critique, revise, adjudicate. Most of the alignment work tends to live here, because optimizing the wrong proxy reliably produces pathological behavior. The reward-hacking and specification-gaming patterns Christian catalogues in The Alignment Problem [1] are one family of examples, and the broader cobra-effect dynamics that Narayanan and Kapoor describe in AI Snake Oil [3] are another. Deliberation tends to surface those mis-specifications early, because the proposer and the certifier are no longer the same component.
Suppose you've fixed your total parameter budget and are deciding whether to spend it on one large model or on several specialists that sum to the same budget plus a small fusion head. Under reasonable assumptions (heterogeneous inputs, subtasks that can be handled mostly independently, decorrelated specialist errors), the staged mid-to-late fusion approach lowers total risk on two fronts. Each specialist keeps its bias low on its own slice, and the spread of their combined errors stays small because the errors aren't correlated across slices. Robust decision rules then cap the worst-case influence of any single agent, which a monolithic system on the same budget can't do when one of its subtask distributions starts to drift.
Ensembles also expose uncertainty in a way monoliths can't, through outright disagreement. When two specialists return different answers, the system has a clear signal it can act on, like escalating to deliberation, requesting more evidence, or deferring to a judge. A monolith experiencing the same internal uncertainty surfaces it less reliably. Calibration and self-consistency help, but the signal is harder to extract than agent disagreement.
That signal is only as trustworthy as the disagreement is real. If you can't actually verify that two agents ran the computations they claim, disagreement collapses into noise, and any deliberation built on top of it inherits that ambiguity. We come back to that point in Section IV.
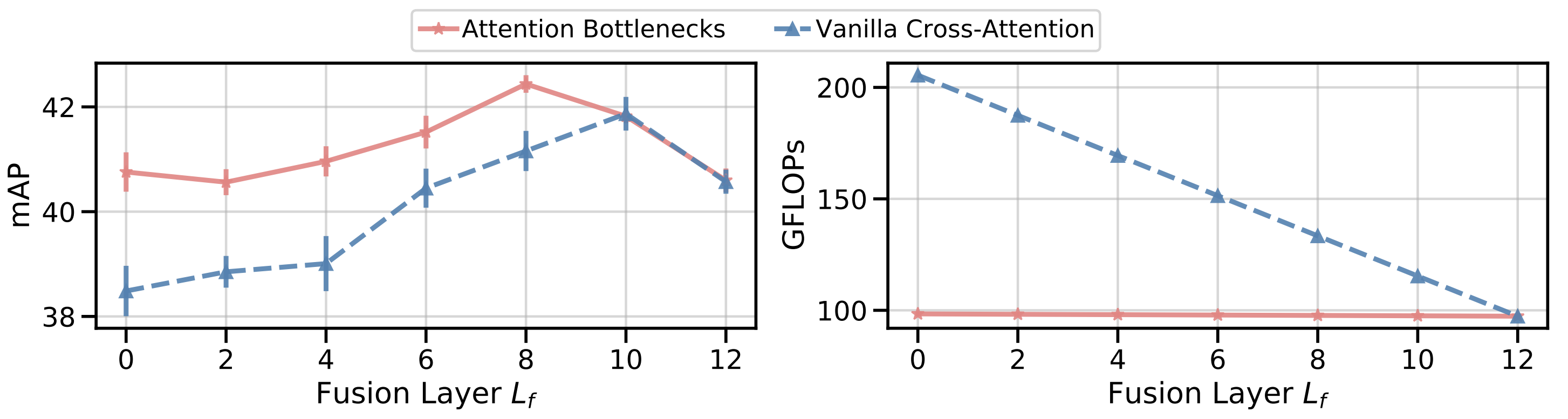
Nagrani et al., NeurIPS 2021 [11]. Attention Bottlenecks for Multimodal Fusion. Attention bottlenecks (red) hold compute roughly flat across fusion depths while matching or beating vanilla cross-attention (blue), which only catches up at much higher compute and at later fusion points. A few "messenger" tokens passing only high-level information between streams keep accuracy high while compute stays nearly flat.
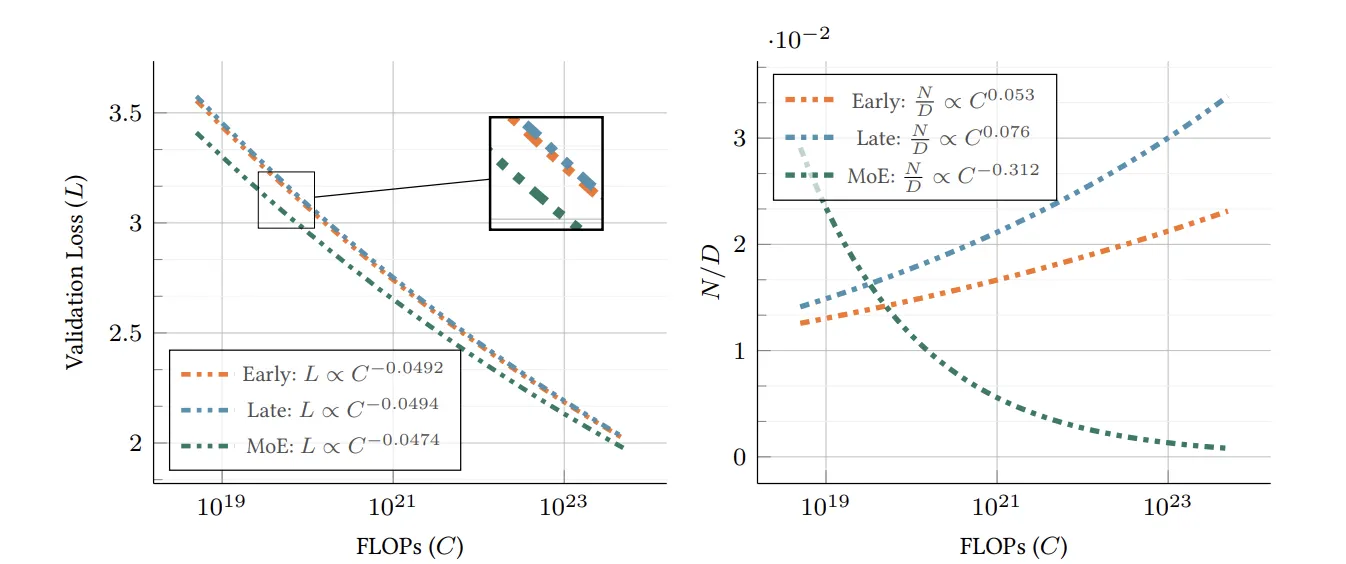
Shukor et al., ICCV 2025 [12]. Apple's scaling laws for native multimodal models. With the same training budget, all designs improve at similar rates but want different allocations. Early fusion matches late fusion at smaller model size if fed more data. Late fusion prefers bigger models. Sparse mixture-of-experts shows the most favorable scaling exponent in this regime, preferring smaller models trained on more data.
IV. Why a Multi-Agent System Needs a New Substrate
A multi-agent system at scale needs more than competent components. It needs infrastructure for discoverability, accountability, bounded action, and provenance. Mollick makes a related argument for human-AI teams in Co-Intelligence [2]: capability tends to come from how the collaboration is architected, not from raw model size alone. The same architecture-as-capability logic holds inside the model layer too.
Centralized pipelines can simulate some of these properties, but they don't easily reproduce the variance, incentives, and audit guarantees a coordinated system actually requires. Four structural problems below make the case concrete, and each implies a property the substrate has to provide.
Specialists are distributed across organizations. The expertise a coordinated AI system needs is not concentrated in one provider. It sits in models trained by different teams, on different data, with different incentives and release policies. A substrate has to make those specialists discoverable, callable, and payable across organizational boundaries, so a swarm can compose them without anyone having to merge into a single provider.
Separation of duties has to be enforceable. In a monolithic system, the same component plans, executes, and certifies. In a multi-agent system, planner, executor, judge, and critic are different by design. But that separation is only meaningful when "who said what" is auditable. Disagreement between agents has to be a verifiable signal rather than an unfalsifiable claim, or any alignment property built on inter-agent oversight collapses.
Intent must compile to bounded action. Non-deterministic LLM output shouldn't be the last layer between the system and the world. The architecture needs a typed, bounded action surface, and each action has to be traceable back to the inference that proposed it.
Memory must persist with provenance. A multi-agent system needs large, mutable memory (embeddings, episodic logs, policy checkpoints) that any inference can cite, along with a guarantee that the cited slice was actually the slice consulted.
These properties don't appear by accident in centralized pipelines. They're protocol properties, and a network of sovereign, proof-carrying agents needs a chain that provides them as primitives. The next section walks through how Theseus does that.
V. How Theseus Delivers the Substrate
Theseus is a chain designed to treat ML inference as a state transition the consensus layer can reason about, instead of a black box bolted to the side of one. The mechanisms below are how that idea actually gets implemented.
Verifiable inference (Tensor Commits). Most chains record only the fact that a model ran. Theseus carries a succinct cryptographic proof that the declared model produced the declared outputs, addressable down to specific rows, channels, or sub-tensors. The underlying construction is Terkle Trees, a tensor-native authentication structure introduced in [15], and it's cheap on both sides. On LLaMA2, Tensor Commits add 0.97 percent prover overhead and 0.12 percent verifier overhead on top of inference, and a verifier without a GPU can check an inference without re-running it. Fusion layers, judges, and critics can then weigh evidence rather than reputation, and MoE routing becomes auditable as long as the routing computation is itself committed.
Deterministic intent (SHIP). SHIP is a domain-specific language that compiles model outputs into a small, bounded set of auditable operations. The execution path is explicit: inference, then SHIP compilation, then proof check, then runtime execution. Nothing in that pipeline lets free-form text silently become a privileged action, and the model has no opportunity to hallucinate a function, misplace a parameter, or smuggle an unsafe construct between the proposal and the actual execution.
Agent-native execution (AIVM). Instead of running on top of the Ethereum Virtual Machine (EVM), Theseus ships its own AI Virtual Machine designed for ML workloads. Tensor operations are first-class instructions, proof checks happen at the language level, and execution is deterministic in the operations consensus depends on (numerical results are reproducible up to a specified tolerance). Models and agents are first-class objects on the chain, and gas charges for the actual tensor work and amortizes across agents that end up calling the same model. Two rules hold the system together at every block: every inference on chain has to include a valid Tensor Commit proof, and every model or context an inference references has to be provably retrievable at the same block.
Memory with provenance (TheseusStore). The chain itself holds the critical state. Bulky context (embeddings, weights, episodic logs) lives in TheseusStore, with cryptographic anchors back to the chain so any inference can cite the exact memory slice it consulted. Storage miners post a stake, prove they still hold the data, and earn fees for it. The data is stored redundantly across nodes, so individual nodes can fail without anything getting lost. The effect is that memory becomes a protocol guarantee rather than a best-effort sidecar.
Economics that price contribution. Multi-agent systems only stay healthy when specialists are getting paid for marginal value. Model owners earn usage fees, dishonest provers lose their stake (slashing), and proof costs amortize across the many agents that share the same model. A built-in order book pushes prices toward marginal cost without requiring off-chain brokers, and gas is predictable enough that you can scale deliberation (more critics, more judges, more rounds) without the overhead becoming prohibitive.
The pieces compose end-to-end. A specialist agent registers itself by publishing a manifest (what it does, how to call it, who can call it) and posting a stake, which is what makes it discoverable and accountable in the first place. Its weights and any context it needs live in TheseusStore. When a workflow runs, the planner calls the retriever and the coder, the safety checker vets their outputs, a judge fuses the decisions, and each step along the way carries a proof. High-stakes outputs then compile through SHIP into a small set of bounded actions (payments, contract calls, tool invocations) that stay tied back to the inferences that proposed them. Settlement runs on the same path. Usage fees flow to the contributing agents, dishonest provers lose their stake, and the fusion layer can weight agents by track record under proof rather than by perceived eloquence.
If general intelligence shows up, we think it's going to look more like a market of independent agents with their own incentives than like one very large model. The hard problem isn't training the next biggest one. It's getting many capable models to disagree productively, check each other's claims, and combine their work in ways an outside party can actually audit. We don't think you can do that on cloud APIs and signed receipts. You need a chain that treats verifiable inference, bounded action, persistent memory, and paid contribution as primitives. That's what we're building at Theseus.
References
[1] Christian, B. (2020). The Alignment Problem: Machine Learning and Human Values. W. W. Norton.
[2] Mollick, E. (2024). Co-Intelligence: Living and Working with AI. Portfolio.
[3] Narayanan, A., & Kapoor, S. (2024). AI Snake Oil: What Artificial Intelligence Can Do, What It Can't, and How to Tell the Difference. Princeton University Press.
[4] Gambelin, O. (2024). Responsible AI: Implement an Ethical Approach in Your Organization. Kogan Page.
[5] Guerraoui, R., Gupta, N., & Pinot, R. (2024). Robust Machine Learning: Distributed Methods for Safe AI. Springer Nature Singapore.
[6] Carpenter, P. (2024). FAIK: A Practical Guide to Living in a World of Deepfakes, Disinformation, and AI-Generated Deceptions. Wiley.
[7] Beckman, M. (2025). Some Future Day: How AI Is Going to Change Everything. Skyhorse.
[8] Viggiano, G. (Ed.). (2022). Convergence: Artificial Intelligence and Quantum Computing. John Wiley & Sons.
[9] Kurzweil, R. (2024). The Singularity Is Nearer: When We Merge with AI. Viking.
[10] Khan, A., et al. (2024). "Debating with More Persuasive LLMs Leads to More Truthful Answers." ICML 2024.
[11] Nagrani, A., et al. (2021). "Attention Bottlenecks for Multimodal Fusion." NeurIPS 2021.
[12] Shukor, M., et al. (2025). "Scaling Laws for Native Multimodal Models." ICCV 2025.
[13] Baser, O., et al. (2025). "ModalFidelity: Modality Reduces Deepfake Detection Error Exponentially." TMLR 2025.
[14] Ng, A. (2024). "Agentic Design Patterns Part 1: Four AI Agent Strategies That Improve GPT-4 and GPT-3.5 Performance." The Batch, DeepLearning.AI, March 20, 2024.
[15] Baser, O., et al. (2026). "TensorCommitments: A Lightweight Verifiable Inference for Language Models." arXiv:2602.12630.